Some time ago I had the wonderful opportunity of designing a system that could handle a high volume of data. I can’t go into the details of the project, but it was by far the most challenging project I have worked on in terms of scale.
Even though I’m not allowed to share code or architecture diagrams of the solution, I can share part of the thinking process. I hope you can use these learnings in your own projects.
Often, I see people overthink their solutions or go for code optimizations that might not be needed. Usually, just using common sense and a bit of experience can get you a long way. It’s only when you hit big numbers that you have to start paying attention to details to keep things running smoothly and at minimal cost.
Note: When you reach this scale for your project, reach out to your local Microsoft representative. They can help you to get started by either assigning a Cloud Solution Architect or even FastTrack engineers to assist you with the architecture and cost optimizations.
Part of the problem
Part of the system had to process large files with records, which were uploaded to an Azure Blob Storage.
TLDR solution
With the requirements of both CPU and IO work, process the input as soon as possible and the ability to switch to fully event-driven in the future, we decided to use Azure Functions in combination with Azure Event Grid for the file triggers. I validated this with a local CSA and also a GBB (Global Black Belt) at Microsoft and finished the design phase of with a series of PoCs to validate.
Design for cost
Typically, with common sense and some monitoring, you can easily keep your costs under control. However, at a certain size the numbers start to matter.
Before you implement
There is no use in building a whole system, if you can’t afford to run it. Having a good estimate of the costs is crucial. You can use the Azure Pricing Calculator to get an estimate of the costs. Typically, this is quite straightforward to use. But of course, I would not write this post if it was not for the details.
With high volume, you need to know the small details of the services you plan to use, a few examples to keep you on your toes for your next big project:
-
Azure Blob Storage: The cost of the storage is quite straightforward. It is cheap storage and can easily handle petabytes of data. The hidden cost on this service is transactions in case you work with lots of small files or reads/writes. The way the customer proposed to work, would cost them more in transactions than everything else together.
Trying to be smart with storage tiers might also turn out to be more expensive than you think. Another customer once told me they would store everything in the archive tier, but planned to rehydrate all files within 1-2 years. Edit: There is now a cold tier as an extra layer between cool and archive. -
Azure SQL: While SQL server has always been a data powerhouse, you need to know how to use it at large volume. What are your keys and indexes? Do you have a single large table? Does all your data belong in a ‘costly’ data store?
During testing we started to notice a performance degradation in both reads and writes (including bulk inserts) with hundreds of millions of records. Of course, it did not help that we had a GUID as key (business requirement). -
Azure Cosmos DB: This is a great service for high volume, but you need to know how to use it. The hidden cost of this service is not in the storage, but in the RU/s. Be sure to correctly partition your data so you can do point reads rather than full container scans. Be sure to monitor your RU/s usage and you can even query the used RUs per query in your code.
-
Azure Service Bus (or any messaging service): Once you start to work with large volumes (of messages), you will need to use multiple messaging units, each on multiplying the cost.
Compare similar services
Normally you would compare services based on their features, and with a few exceptions cost should not be the deciding factor. Of course, if we look at huge numbers, the cost does matter.
As an example, for most (operational) data solutions you will typically choose between services like Azure SQL and Azure Cosmos DB. But storing petabytes of data in both services is quite costly. An option could be to only keep the last week of data in either service, and offload the rest to a cheaper storage solution.
PoC your unknowns
When you start to work with large volumes, you will hit unknowns and make assumptions. It is crucial to have a good understanding of these unknowns before you start building your system. Depending on your requirements, you will have your own questions, but here are a few examples:
- Is the integration between the services as I expect?
- If I read a file line by line, is that a single batched transaction or multiple? (Hint: with the C# SDK, you get batched reads.)
- What is the representative cost for a full day of data/transactions? (You can run a PoC for a few hours or day and then scale up the numbers to years. Getting the factor right already helps a lot.)
- Can service X or service Y handle the volume I expect? How do the service limits in the docs compare with what I experience? Do I notice service degradation? (Service degradation is often a result of your choice/implementation.)
A Proof-of-Concept (PoC) is a minimal project with the intention to test and validate these questions. It is not a prototype, nor a production-ready system. It is a small project that you can (and should) throw away after you have validated your assumptions. This can be as simple as starting from one of the sample projects, do some minor tweaks and run it for a few hours.
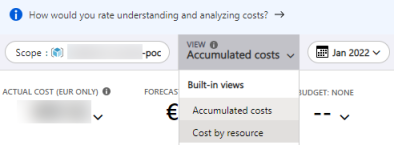
Note: You can view the cost per resource in the Azure Portal. This is a great way to validate your assumptions. It is however important to know that this data can be delayed by up to 24 hours. So, when running PoCs I typically create a new resource for each variation I want to test. This way I can easily compare the costs of each variation.
During implementation
Once you have everything confirmed, you can start building. For this kind of projects, I have always followed the saying “measuring is knowing”. Due to the importance of both performance and cost, I ask the team to finish each sprint with a load test and a cost analysis. This allows us to catch high impact changes made during the sprint and will make troubleshooting easier.
Bonus
In the past I have written a blog post on marginal gains regarding to high volume processing. This can be a good addition on top of this post.