This is a story I had to postpone to not give away too much information about which project I was working on. But the learnings are too good not to share. So here we go.
TLDR: During this project, we ran into a very weird behavior where Azure Functions scaled up to our defined limit to process files, but after some time slowly dropped back and processed the rest of the files at a much slower pace. We ended up troubleshooting with several product teams at Microsoft and turned out that internal errors triggered a throttling mechanism. Rewriting the code to Durable Functions fixed our issues.
The project
Without going into too much detail, the project was about processing files. The files were uploaded to an Azure Blob Storage, and we had an Azure Function that was triggered by the blob creation (over Event Grid). The function would then process the file, do some CPU work and store output in multiple places, including Cosmos DB.
The issue
A picture says more than a thousand words, so let me show you the graph of the issue:
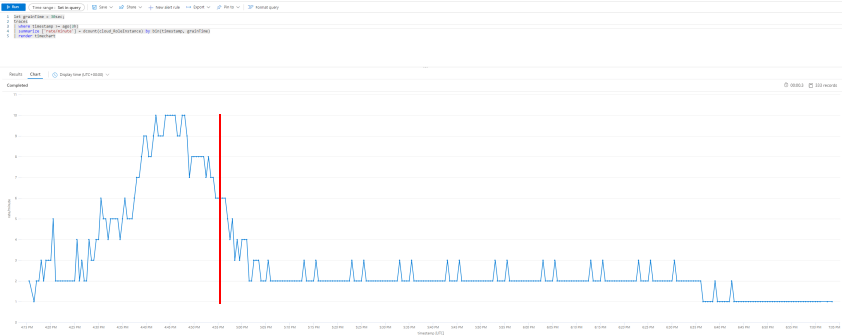
You can generate these graphs by using following query in Azure Monitor:
let grainTime = 30sec;
traces
| where timestamp >= ago(4h)
| summarize ['rate/minute'] = dcount(cloud_RoleInstance) by bin(timestamp, grainTime)
| render timechart
As mentioned in the previous post, we had a separate Azure Function generating a batch of files. The graph shows our consumer picking up the generated files and scale out to the maximum of 10 instances. So far, so good. But even before file generation completed (approximately at the red line), we started to see a drop off in the number of instances. The rest of the files were processed at a much slower pace, with a ’long tail'.
The investigation
When you run in unexpected behavior, it is always good to start with the basics. We checked the logs for errors, the code, the configuration, … Even the CPU and memory usage of the instances.
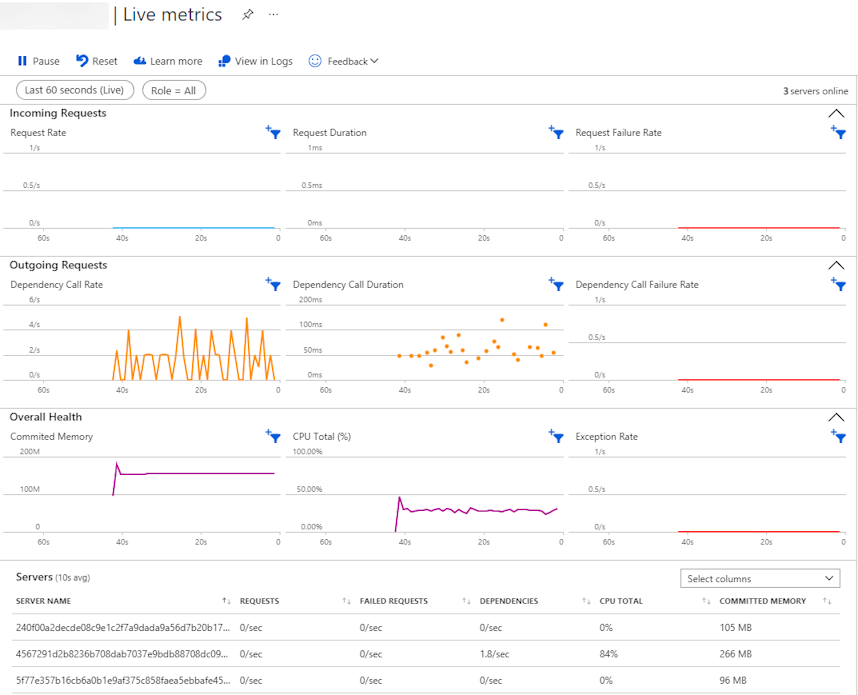
The above image shows the live metrics of a single instance. The memory working set is within reasonable range, showing that we did not have memory leaks or other memory issues. If we had, we would have known rather soon as we were processing files of up to hundreds of gigabytes at some point to test the limits of the system. The same goes for the CPU usage.
We also did not have any request failures, dependency failures, or other errors in the logs. So, it was time to check in on the other dependencies.
Azure Blob Storage: As our file generation service was able to easily write up to 100x the number of files we were processing, we were sure that the Blob Storage throughput was not the bottleneck. A quick check on the metrics confirmed this.
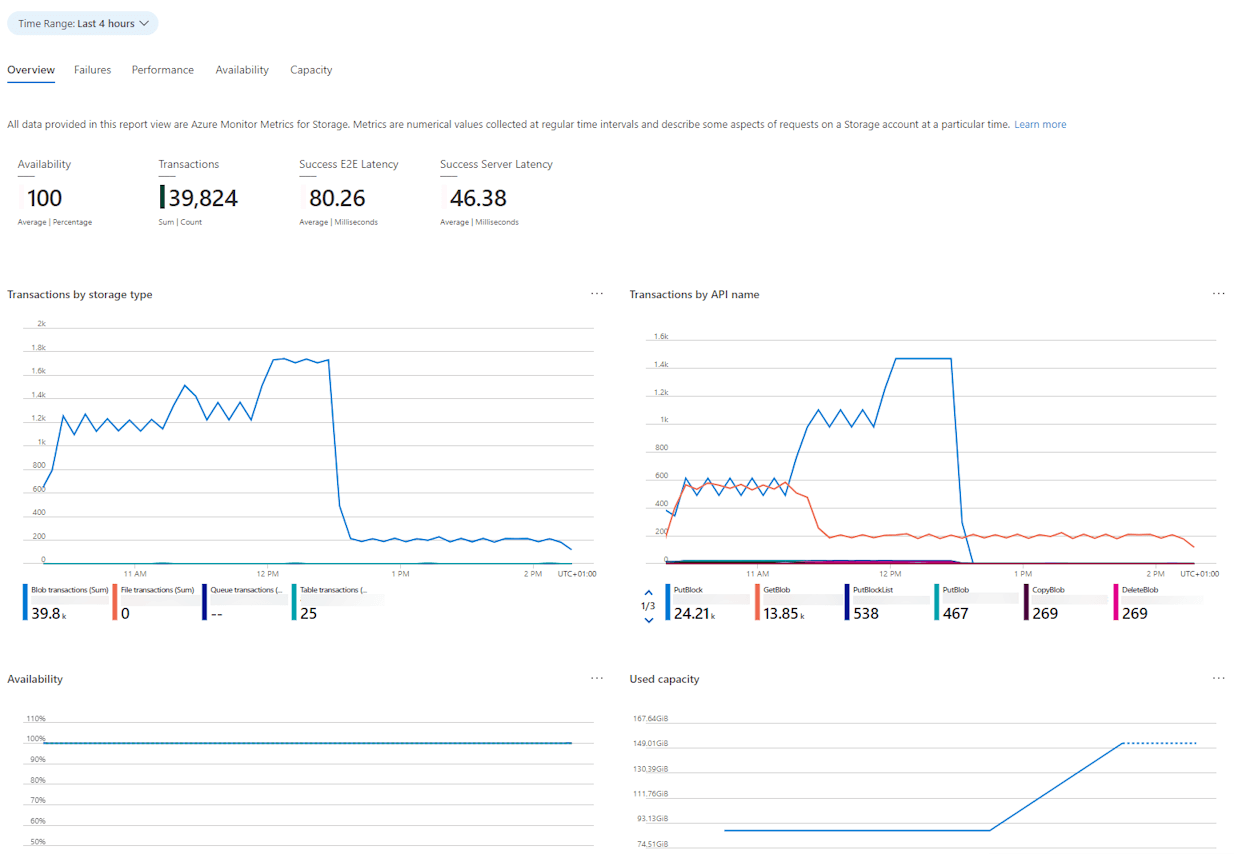
There was no flat toplining showing that we were hitting the limits of the storage account. On the right graph, you can see the ramp-up of the file generation service (PutBlock), but also the early drop-off of our consumer (GetBlob).
Azure Cosmos DB: Since we spent quite some time finetuning the setup of our Functions in regarding to downstream throughput on Azure Cosmos DB and Azure SQL Database, we were sure that we were not hitting the limits of the database. The metrics confirmed this as well.
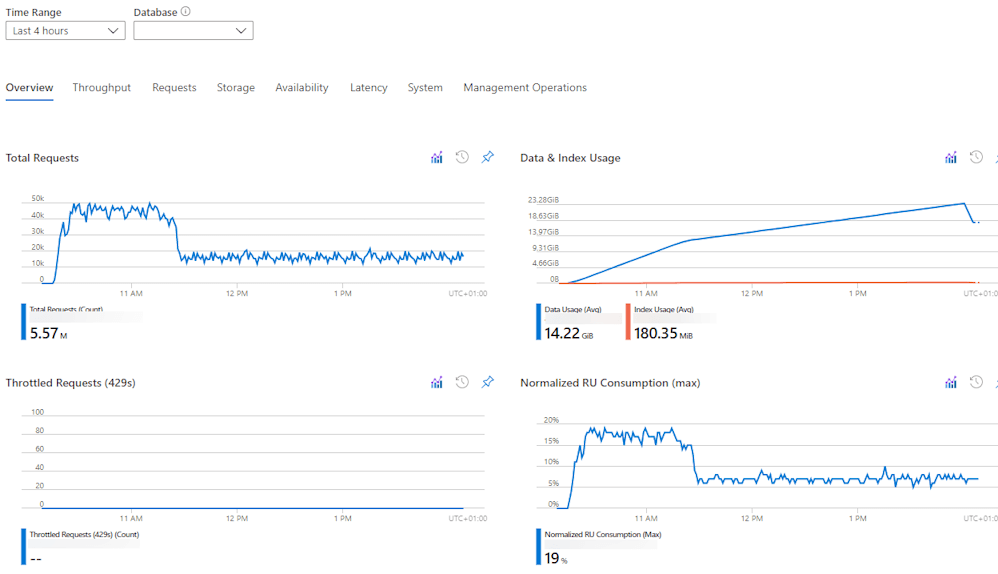
In this particular run, we topped out at around 20% of the provisioned RU/s. The graph also shows a similar drop-off as the Blob Storage graph.
Azure Event Grid: The Event Grid was the last dependency in this particular test setup. Again, the graph was very similar.
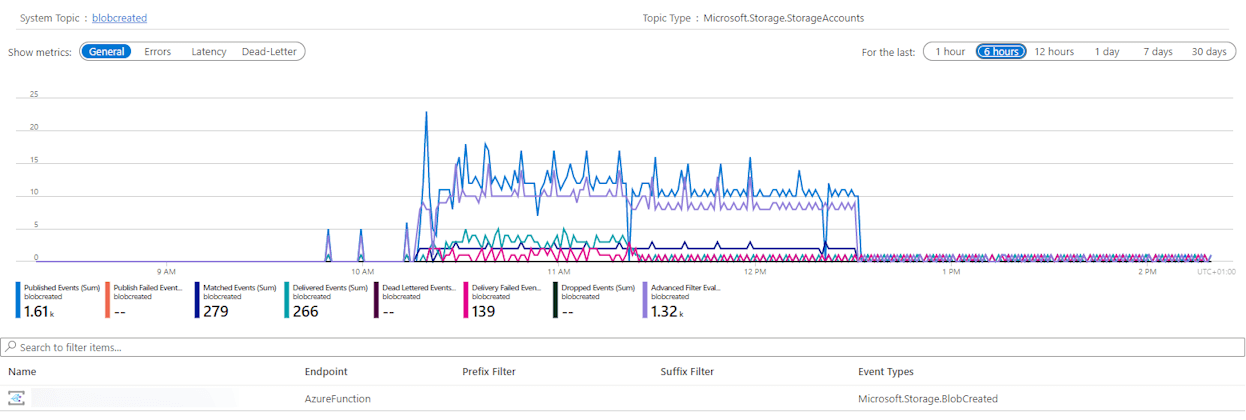
Interesting here are the different drop-offs. First of all, we have the green graph showing the ‘Delivered Events’, which starts to drop at the same time our Azure Functions start to scale down. Then about an hour later we have the ‘Published Events’ (blue) and ‘Advanced Filter Evaluations’ (purple) that go down once our file generation service stops. It is clear that there was a real issue ‘somewhere’ in the system as files were still being generated, but not processed.
Alternatives?
While waiting on feedback from the product teams at Microsoft, we considered a few other options to move forward:
- Move to Durable Function chaining where the initial Function acts on the trigger, but processing is in a chained function. This required some rework, but was a good option to consider and test out.
- Introduce Azure Service Bus to throttle the incoming events from Event Grid. However, this takes away part of the flexibility in scaling the processing power.
Of course, I wanted to know the root cause of our issue as I have never seen this kind of behavior before.
The issue
After running trace captures on the Azure Functions, working with the Azure Cosmos DB team and the Azure Event Grid team, we were sent some internal errors triggered between Azure Event Grid and the consumer Azure Function.
In short, Azure Event Grid calls the Azure Function by using an HTTP call. It expects a response within 30 seconds. Since we were processing large files, our Azure Function was taking several minutes to complete. Azure Event Grid sees this as a failed execution and retries the call for that given event.
Since the Azure Function did its job, we did not pay attention to this timespan and simply had a check in place for duplicate triggers and only process once. So, while we thought we had everything running fine, Azure Event Grid was always getting a ‘failed’ request on the first call of each event, thus throttling in sending new events.
The solution
One of our alternate solutions was actually the right choice: Durable Functions. This not only fixed the issue with Azure Event Grid by correctly responding to the triggers, but also allowed us to better manage the parallellism (threads) on a single instance.
Lessons learned
Know your services and read the docs (they keep improving)!
- Avoid long running functions when possible.
- Even though Azure does allow for long running functions, keep in mind how you trigger the function and if that trigger expects a timely response.
- Use Durable Functions to assist with longer executions or long running workflows. This allows for a quick ‘acknowledgement’ to the trigger and then continue processing in the background.
- If you somehow keep the long running task within a normal Azure Function, make sure all background tasks are complete when you exit the function as the runtime considers the execution as having completed successfully.